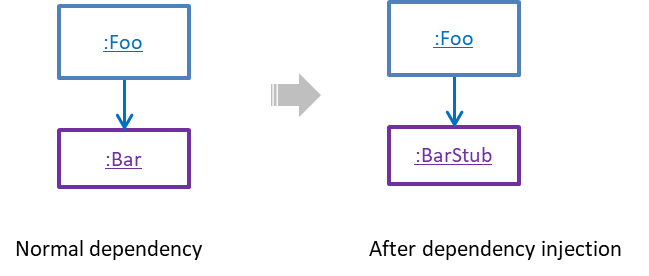
A proper unit test requires the unit to be tested in isolation so that bugs in the code the unit depends ondependencies cannot influence the test i.e. bugs outside of the unit should not affect the unit tests.
If a Logic class depends on a Storage class, unit testing the Logic class requires isolating the Logic class from the Storage class.
Stubs can isolate the Software Under Test (in this case, the unit being tested)SUT from its dependencies.
Stub: A stub has the same interface as the component it replaces, but its implementation is so simple that it is unlikely to have any bugs. It mimics the responses of the component, but only for the a limited set of predetermined inputs. That is, it does not know how to respond to any other inputs. Typically, these mimicked responses are hard-coded in the stub rather than computed or retrieved from elsewhere, e.g. from a database.
Consider the code below:
class Logic {
Storage s;
Logic(Storage s) {
this.s = s;
}
String getName(int index) {
return "Name: " + s.getName(index);
}
}
interface Storage {
String getName(int index);
}
class DatabaseStorage implements Storage {
@Override
public String getName(int index) {
return readValueFromDatabase(index);
}
private String readValueFromDatabase(int index) {
// retrieve name from the database
}
}
Normally, you would use the Logic class as follows (note how the Logic object depends on a DatabaseStorage object to perform the getName() operation):
Logic logic = new Logic(new DatabaseStorage());
String name = logic.getName(23);
You can test it like this:
@Test
void getName() {
Logic logic = new Logic(new DatabaseStorage());
assertEquals("Name: John", logic.getName(5));
}
However, this logic object being tested is making use of a DataBaseStorage object which means a bug in the DatabaseStorage class can affect the test. Therefore, this test is not testing Logic in isolation from its dependencies and hence it is not a pure unit test.
Here is a stub class you can use in place of DatabaseStorage:
class StorageStub implements Storage {
@Override
public String getName(int index) {
if(index == 5) {
return "Adam";
} else {
throw new UnsupportedOperationException();
}
}
}
Note how the StorageStub has the same interface as DatabaseStorage, is so simple that it is unlikely to contain bugs, and is pre-configured to respond with a hard-coded response, presumably, the correct response DatabaseStorage is expected to return for the given test input.
Here is how you can use the stub to write a unit test. This test is not affected by any bugs in the DatabaseStorage class and hence is a pure unit test.
@Test
void getName() {
Logic logic = new Logic(new StorageStub());
assertEquals("Name: Adam", logic.getName(5));
}
In addition to Stubs, there are other type of replacements you can use during testing. E.g. Mocks, Fakes, Dummies, Spies.
Resources
- Mocks Aren't Stubs by Martin Fowler -- An in-depth article about how Stubs differ from other types of test helpers.
Exercises
Purpose of stubs
Stubs help us to test a component in isolation from its dependencies.
True